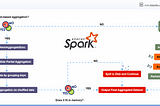
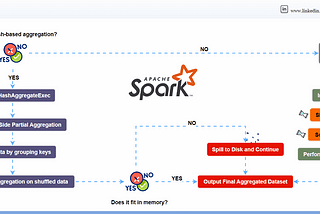
InStackademicbyShanojApache Spark Aggregation Methods: Hash-based Vs. Sort-basedApache Spark provides two primary methods for performing aggregations: Sort-based aggregation and Hash-based aggregation. These methods are…Mar 19, 2024Mar 19, 2024
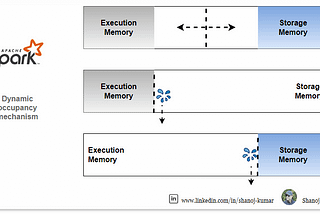
InStackademicbyShanojUnderstanding Memory Spills in Apache SparkMemory spill in Apache Spark is the process of transferring data from RAM to disk, and potentially back again. This happens when the…Mar 11, 2024Mar 11, 2024
InStackademicbyShanojApache Spark Optimizations: Shuffle Join Vs. Broadcast JoinsApache Spark is an analytics engine that processes large-scale data in distributed computing environments. It offers various join…Jan 15, 20241Jan 15, 20241
InStackademicbyShanojApache Spark 101: Dynamic Allocation, spark-submit Command and Cluster ManagementApache Spark's dynamic allocation feature enables it to automatically adjust the number of executors used in a Spark application based on…Dec 11, 2023Dec 11, 2023
InStackademicbyShanojApache Spark 101: Understanding DataFrame Write API OperationApache Spark is an open-source distributed computing system that provides a robust platform for processing large-scale data. The Write API…Dec 4, 2023Dec 4, 2023
InStackademicbyShanojApache Spark 101: Shuffling, Transformations, & OptimizationsShuffling is a fundamental concept in distributed data processing frameworks like Apache Spark. Shuffling is the process of redistributing…Sep 20, 20231Sep 20, 20231
InStackademicbyShanojApache Spark 101:Schema Enforcement vs. Schema InferenceWhen working with data in Apache Spark, one of the critical decisions you’ll face is how to handle data schemas. Two primary approaches…Sep 30, 2023Sep 30, 2023
InStackademicbyShanojApache Spark 101: select() vs. selectExpr()Column selection is a frequently used operation when working with Spark DataFrames. Spark provides two built-in methods select() and…Oct 12, 2023Oct 12, 2023
InStackademicbyShanojApache Spark 101: Read ModesApache Spark, one of the most powerful distributed data processing engines., provides multiple ways to handle corrupted records during the…Oct 21, 2023Oct 21, 2023
InStackademicbyShanojApache Spark 101: Understanding Spark Code ExecutionApache Spark is a powerful distributed data processing engine widely used in big data and machine learning applications. Thanks to its…Nov 15, 2023Nov 15, 2023
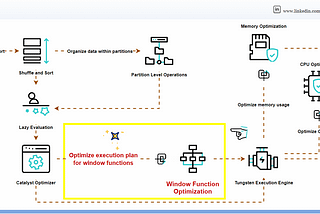
InStackademicbyShanojApache Spark 101: Window FunctionsApache Spark offers a robust collection of window functions, allowing users to conduct intricate calculations and analysis over a set of…Nov 27, 2023Nov 27, 2023